해당 포스트는 아래의 강의 수강 후 작성됨을 알려드립니다.
[지금 무료] [데브원영] 아파치 카프카 for beginners | 데브원영 DVWY - 인프런
데브원영 DVWY | 아파치 카프카란 무엇일까? 아파치 카프카는 어떻게 동작할까? 아파치 카프카의 개념은 무엇이 있을까? 궁금하시다면 이 강의를 선택하세요😎, 아파치 카프카(Apache Kafka), 핵심을
www.inflearn.com
아파치 카프카는 무엇인가?
데이터를 전송하는 소스 애플리케이션(Source Application)과 데이터를 받는 타겟 애플리케이션(Target Application)이 있는데, 하나의 소스 애플리케이션과 하나의 타겟 애플리케이션의 데이터 전송에서 점점 소스 애플리케이션과 타겟 애플리케이션이 많아지며 데이터 전송 라인이 많아지게 되었다.
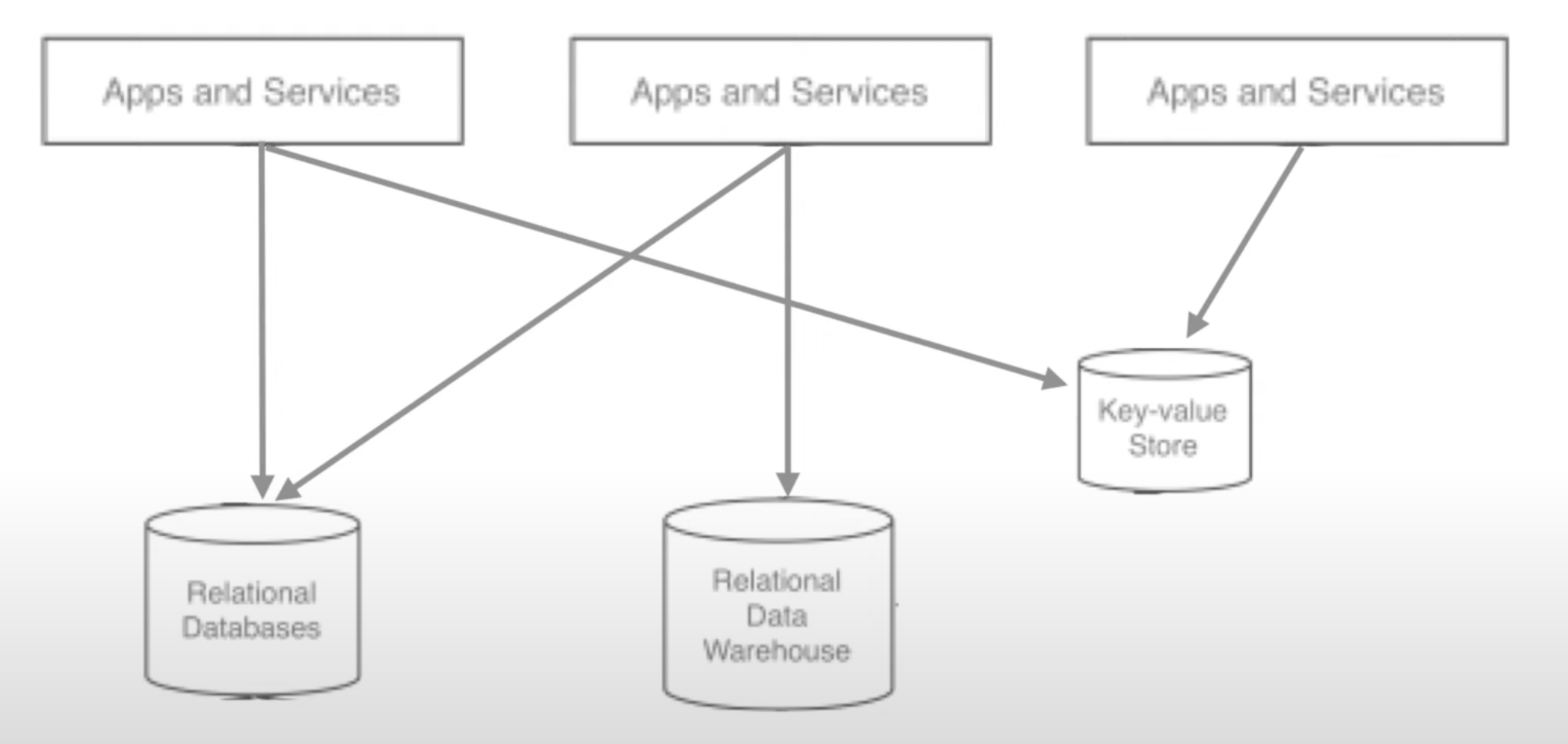
따라 배포와 장애에 어려움이 생기며, 데이터 전송시의 프로토콜 포맷의 파편화가 심해졌다.
이처럼되면 추후 유지보수가 매우 힘들어진다.
아파치 카프카는 이런 것을 해결하기 위해 만들어졌다고 말할 수 있다.
현재 아파치 카프카는 오픈소스로 운영되고 있다.

아파치 카프카를 통해 소스 애플리케이션은 카프카에 데이터를 전송하고, 타겟 애플리케이션은 카프카에서 데이터를 가져다 사용하게된다.
카프카에는 데이터를 담는 토픽이라는 개념이 있다. 큐로 이해하면 된다.
카프카에서 데이터를 데이터를 넣는 역할은 Producer(프로듀서)라고 하며, 가져가는 역할은 Consumer라고 한다.
왜 카프카를 사용하나?
데이터 흐름에 있어 카프카는 고가용성으로, 문제 상황이 생기는 경우에도 데이터 손실없이 복구할 수 있다.
또한 카프카는 낮은 지연(latency), 높은 처리량을 가지고 있다.
카프카 토픽
토픽은 카프카 내부에서 여러개 만들 수 있으며, 데이터베이스의 테이블과 파일 시스템의 폴더와 유사한 성질을 가지고 있다.
토픽은 이름을 가질 수 있으며, 목적에 따라 클릭로그와 같이 무슨 데이터를 가지는지 명확하게 명시하여 추후 유지보수 관리에 편리하게 사용할 수 있다.
하나의 토픽은 여러개의 파티션으로 구성될 수 있다(파티션 번호는 0번부터 시작).
파티션은 큐처럼 쌓이게 된다.(따라 나가는 경우에도 처음에 들어온 데이터 부터 나가게 된다.)

이 때, 컨슈머가 데이터를 가져가도 파티션 내에 있는 데이터는 사라지지 않는다.
새로운 컨슈머가 나타나면 이 데이터를 가져갈 수 있는데, 이 때 이 컨슈머는 기존 컨슈머와 그룹이 달라야 하며, auto,offset.reset이 earliest로 설정되어 있어야 한다.
파티션이 2개인 경우
토픽에 데이터가 들어가는 경우 2개의 파티션 중 어느 것에 들어가야 할까?
이 때, 데이터를 보내는 프로듀서는 키를 지정할 수 있다.
키가 null인 경우 round-robin으로 파티션이 지정되며, 키가 있는 경우에는 해시값을 구하고 특정 파티션에 할당한다.
파티션은 늘릴 수 있지만 늘린 후 삭제가 불가능하다.
브로커
카프카에서 브로커는 카프카에 설치되어 있는 서버 단위를 말한다. 보통은 3개 이상의 브로커를 사용하는 것을 권장한다.
복제
replication은 파티션의 복제를 뜻하며, 레플리케이션이 1개라면 피티션은 1개만 존재한다는 의미이다.
레플리케이션이 2이면, 파티션이 원본 1개와 복제본 1개로 존재한다는 의미이다.(원본은 1개)
레플리케이션의 수는 브로커의 수보다 많을 수 없다.
여기서 원본 파티션은 reader patition 이라고 하며, 나머지 파티션은 follower patition 이라고 한다.
이 replication은 고가용성을 위해 사용되며, 하나의 파티션이 사용 불가 상태가 되어버려도 복제본이 존재하니 복구가 가능하다.
복제: ack
프로듀서에는 ack라는 것이 있는데, ack는 0, 1, all 옵션 중 한가지만 골라 사용이 가능하다.
1. ack가 0일 경우
프로듀서가 리더 파티션에 데이터를 전송 후 응답값을 받지 않는다.
따라 데이터가 정상적으로 저장 및 복제가 되었는지 확인할 수 없으며, 따라 속도는 빠르지만 데이터 유실의 위험이 있다.
2. ack이 1일 경우
프로듀서는 데이터 전송 후 리더 파티션으로부터 응답값을 받는다. 다만 복제되었는지는 확인 불가능하다.
따라 데이터를 받은 동시에 리더 파티션에 장애가 일어나면 복제가 일어나지 않아 데이터 유실의 가능성이 커진다.
3. ack이 all일 경우
반대로 리더 파티션의 데이터 저장 및 복제까지의 응답값을 받는다.
따라 데이터 유실은 없지만 속도가 현저히 느려진다.
replication의 개수
레플리케이션의 개수가 많아질 수록 데이터 유실의 위험은 적어지겠지만 그만큼 브로커 리소스 사용량이 늘어난다.
따라 레플리케이션의 개수는 카프카에 들어오는 데이터의 양과 저장시간을 생각해 정해야한다.
파티셔너(Partitioner)
프로듀서의 파티셔너는 중요한 개념 중 하나로, 프로듀서가 데이터를 보낼 때는 무조건 파티셔너를 통해 보내게된다.

파티셔너는 데이터를 토픽의 어떤 파티션에 넣을지 결정하는 역할을 한다.
이는 레코드에 포함된 메세지의 키나 값을 통해 결정된다.
프로듀서에서 파티셔너를 설정하지 않는다면 기본값으로 UniformStickyPartitioner로 설정된다.
메세지 키가 있는 경우
메세지 키를 가진 레코드는 파티셔너에 의해 특정한 hash값으로 생성된다.
그리고 이 hash값을 통해 어느 파티션에 들어갈지 결정된다.
hash값을 사용하게되면, 동일한 메세지 값을 가진 레코드는 항상 동일한 hash값을 얻게되고, 따라 항상 동일한 파티션에 들어가는 것을 보장할 수 있다.
그리고 이는 순서를 지켜 데이터를 처리할 수 있다는 장점을 가지고 온다.
메세지 키가 없는 경우
메세지 키가 없는 레코드는 배치단위로 모여 라운드 로빈의 방식으로 파티션에 들어간다.
따라 메세지 키가 없는 레코드는 적절히 분산 시키는 것이다.
파티셔너 커스텀
프로듀서의 파티셔너는 UniformStickyPartitioner 뿐만 아니라 직접 개발한 파티셔너도 사용이 가능하다.
카프카에서는 커스텀 파티셔너를 만들수 있도록 Partitioner 인터페이스를 제공하고 있다.
커스텀한 파티셔너를 통해 메세지 키나 값 이외에도 토픽이름 등을 사용하여 어떤 파티션에 데이터를 보낼건지 결정할 수 있다.
컨슈머 랙(Consumer Lag)
카프카의 lag은 카프카에서 아주 중요한 모니터링 지표 중 하나이다.
프로듀서가 넣은 데이터는 컨슈머가 가져가게된다.
이 때, 프로듀서가 데이터를 넣는 속도가 컨슈머가 데이터를 가져가게 되는 속도보다 빠르게되는 경우가 생기면 이것을 컨슈머 랙이라고 부른다.
따라 컨슈머 랙은 파티션의 가장 최근 오프셋과 컨슈머 오프셋간의 차이를 말한다.
이 lag 숫자를 통해 현재 토픽에 파이프라인으로 연결되어있는 프로듀서와 컨슈머의 상태 확인이 가능하며, 주로 컨슈머의 상태 확인을 위해 사용하는 경우가 많다.
해당 lag은 파티션 단위로 발생하므로, 하나의 토픽에 여러 파티션이 있으면 lag은 여러개 생길 수 있다.
하나의 토픽에 대해서 lag이 여러개 발생하는 경우 records-lag-max라고 한다.
컨슈머 랙 모니터링 애플리케이션
Kafka-client 라이브러리를 사용해 카프카 컨슈머를 구현할 수 있다.
이 카프카 컨슈머 객체를 통해 현재 lag 정보를 가져올 수 있다.
해당 lag은 저장소에 넣어 실시간으로 모니터링 할 수도 있다.
그러나 컨슈머 단위에서 lag을 모니터링하는 것은 위험하고 운영에 힘이 든다.
컨슈머 로직 단계에서 lag을 수집하는 것은 컨슈머 상태에 디펜던시가 걸리기 때문이다.
컨슈머가 비정상적으로 종료하게되면 컨슈머는 lag 정보를 보낼 수 없어 lag 측정이 불가능해진다.
그리고 컨슈머가 개발될 때마다 컨슈머마다 lag이 저장될 수 있도록 로직을 만들어야 한다.
따라 linkedin에서는 아파치 카프카와 함께 카프카 컨슈머 랙을 효과적으로 모니터링 할 수 있도록 'Burrow'를 내놓았다.
Burrow
버로우는 오픈소스로, Golang으로 작성되어 현재 깃허브에 올라와있다.
버로우는 컨슈머 lag 모니터링을 도와주는 독립적인 애플리케이션이다.
버로우의 3가지 특징은 다음과 같다.
1. 멀티 카프카 클러스터 지원
카프카 클러스터가 여러개여도 버로우 애플리케이션 1개만 실행해 연동하면 모든 클러스터의 lag을 모두 모니터링 할 수 있다.
2. Sliding window를 통한 Consumer의 status 확인
버로우는 슬라이딩 윈도우를 통해 ERROR, WARNING, OK 로 상태를 표현할 수 있다.
3. HTTP API 제공
위의 정보들은 버로우가 정의한 HTTP api에서 확인이 가능하다.
이로인해 버로우는 다양한 생태계 구축이 가능했다.
'스터디 > kafka' 카테고리의 다른 글
| [Apache Kafka] Apache Kafka Study 06: 카프카 컨슈머 애플리케이션 개발(+프로듀서 개발) (0) | 2024.05.30 |
|---|---|
| [Apache Kafka] Apache Kafka Study 05: 카프카 프로듀서 애플리케이션 개발 (0) | 2024.05.24 |
| [Apache Kafka] Apache Kafka Study 03: 카프카 클러스터 운영 (1) | 2024.05.16 |